Hive Architecture Overview: Components and Workflow
Hive is a powerful data warehouse infrastructure built on top of Apache Hadoop. It enables the processing of large-scale datasets using a SQL-like language called HiveQL. Designed for analyzing structured data, Hive provides an efficient and user-friendly interface for developers and analysts to interact with distributed storage and resource management systems.
In this article, we’ll explore the Hive architecture in detail, breaking it down into its core components and workflow.
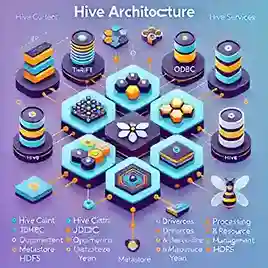
Components of Hive Architecture
The Hive architecture can be divided into four main layers:
-
Hive Client
- Thrift Client: Allows interaction with Hive using various programming languages.
- JDBC/ODBC Applications: Use JDBC and ODBC drivers to connect to Hive for executing queries.
-
Beeline: A command-line tool for running Hive queries directly.
The client layer provides the interface through which users interact with Hive.
-
Hive Services
Hive offers multiple services to manage query execution and metadata storage.- HiveServer2: Acts as the execution engine, processing queries received from clients.
- Driver: Manages the lifecycle of Hive queries, including parsing, compilation, and execution.
- Compiler and Optimizer: Converts SQL queries into execution plans and optimizes them for MapReduce or other processing engines.
- Metastore: Stores metadata about tables, columns, partitions, and other elements within Hive.
-
Processing and Resource Management
Hive translates SQL-like queries into tasks executed in the Hadoop ecosystem.- MapReduce: Handles distributed data processing.
- YARN (Yet Another Resource Negotiator): Allocates resources and manages task scheduling across the Hadoop cluster.
-
Distributed Storage
Hive works seamlessly with distributed storage systems, primarily Hadoop Distributed File System (HDFS). It stores and retrieves large datasets efficiently while ensuring fault tolerance.
Hive Workflow
The following steps outline the general workflow of a Hive query:
- A user sends a query using the Hive client (Beeline, JDBC, or Thrift).
- The query is parsed and converted into an execution plan by the Driver.
- The Compiler analyzes the query and generates a logical execution plan.
- The Optimizer improves the execution plan for better performance.
- The Execution Engine translates the plan into MapReduce tasks and submits them to YARN.
- YARN manages resources and executes the tasks on HDFS.
- Results are returned to the user via the Hive client.
Advantages of Hive Architecture
- Scalability: Hive can process petabytes of data stored across distributed systems.
- Fault Tolerance: Integration with Hadoop ensures resilience to hardware failures.
- SQL-like Interface: HiveQL simplifies data analysis for users familiar with SQL.
- Extensibility: Users can add custom functionalities using UDFs (User Defined Functions).
Applications of Hive
- Data Summarization: Ideal for generating aggregated reports.
- Ad-hoc Analysis: Enables quick querying of large datasets.
- ETL Processes: Useful for Extract, Transform, Load workflows in big data pipelines.
Conclusion
The Hive architecture combines the power of Hadoop’s distributed storage and processing capabilities with the simplicity of SQL. By understanding its components and workflow, developers can unlock the full potential of Hive for efficient data processing and analysis.
If you’re looking to explore more about Hive, check out tutorials on setting up Hive queries, optimizing performance, and integrating with modern big data ecosystems.